Yilong Zhu
Robotics researcher focused on navigation, embodied AI, and spatial intelligence.
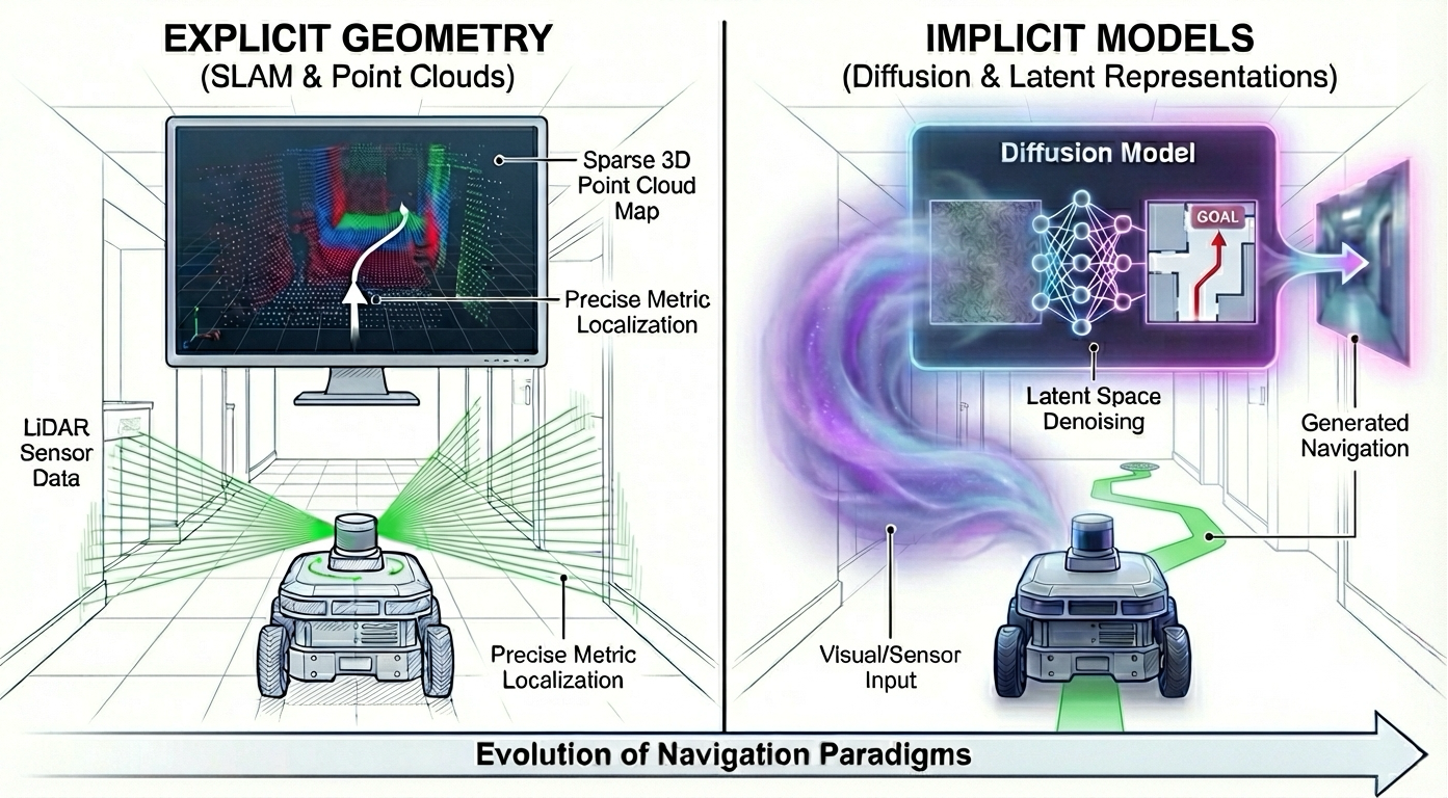
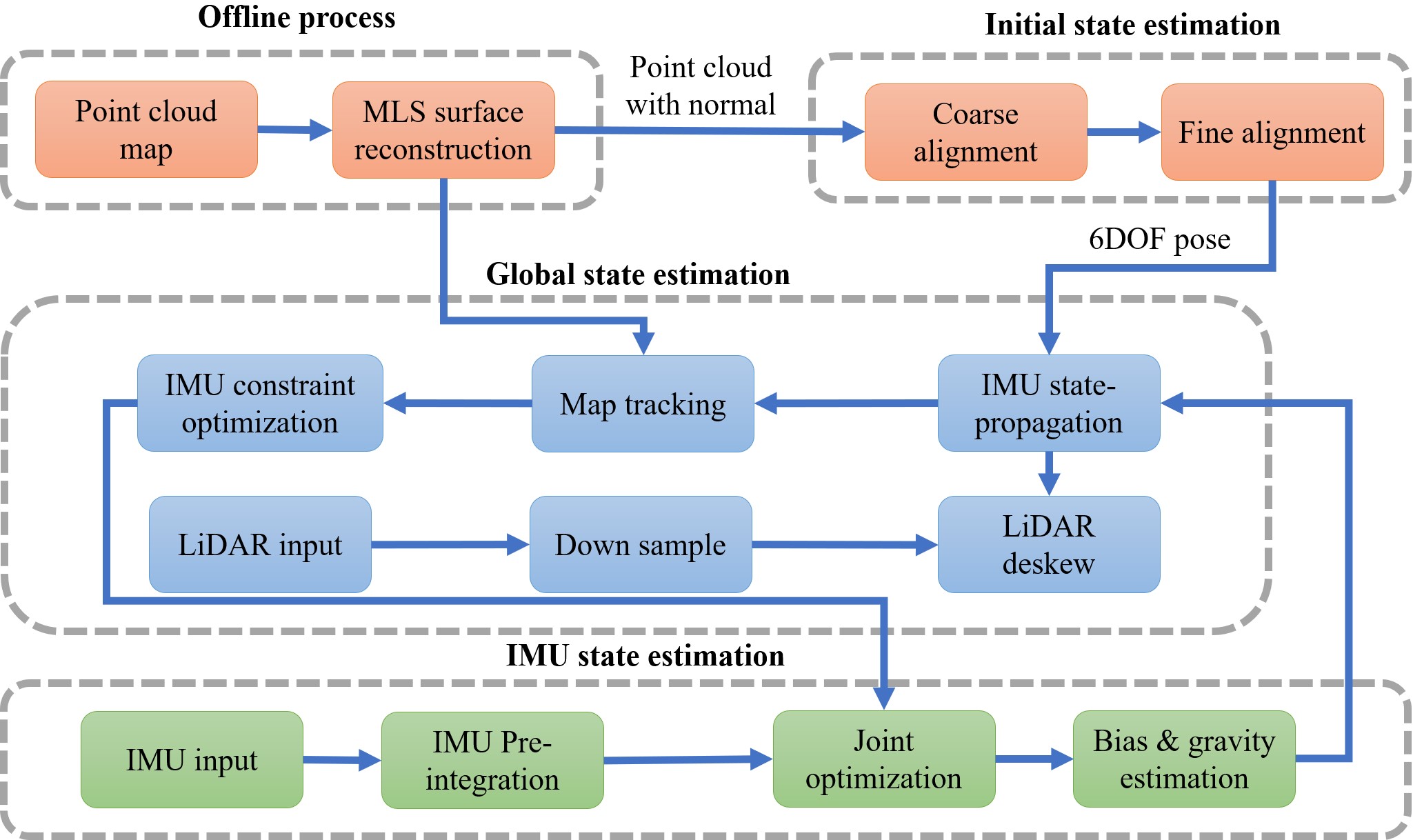
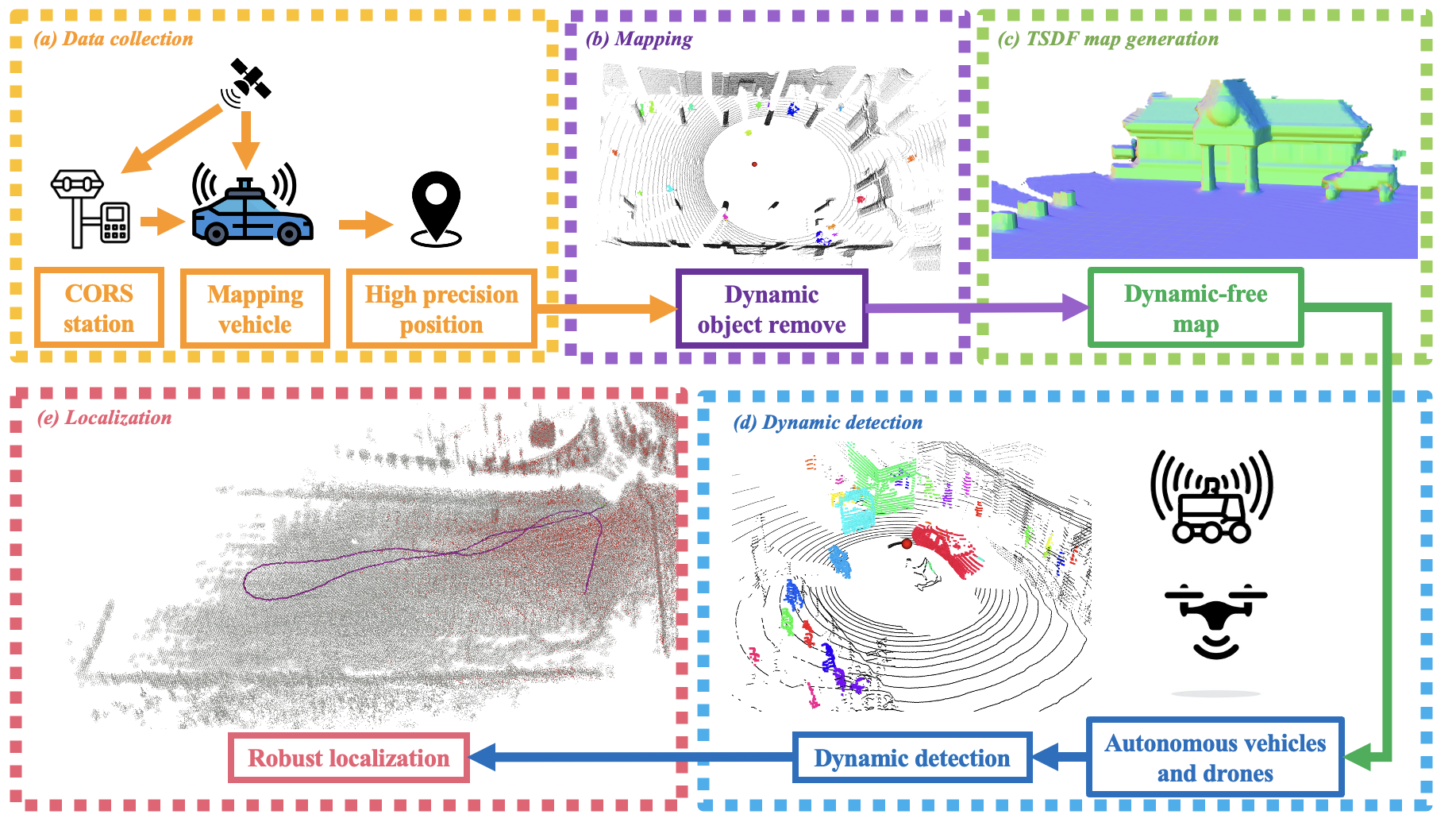
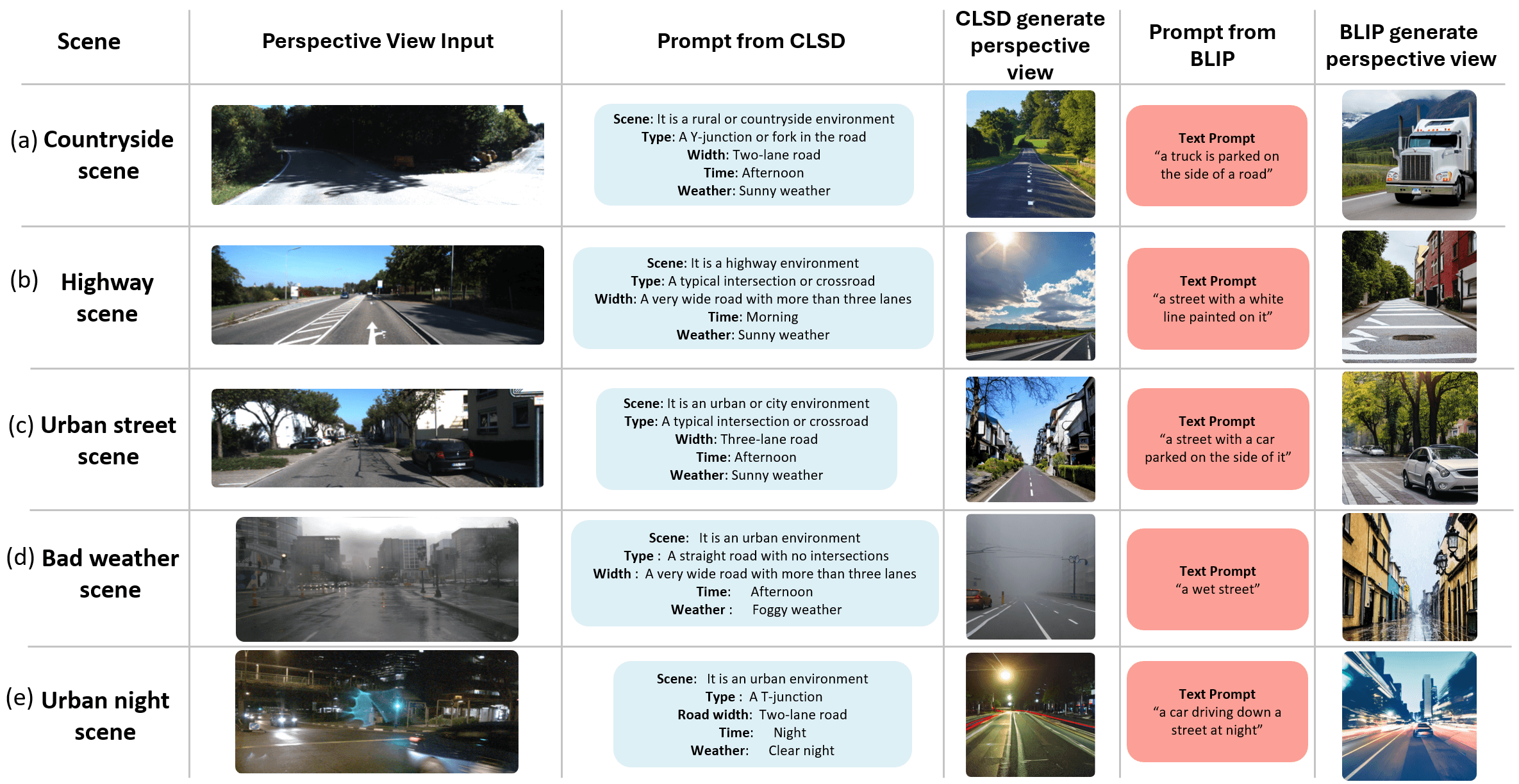
I received my PhD from the Aerial Robotics Group at HKUST, advised by Prof. Shaojie Shen. My research spans robust localization, mapping, cross-view perception, and learning-based navigation.
Currently, I am a VLA Research Intern at China Merchants Lion Rock AI Lab, studying spatial generalization for robotic systems. Previously, I led mapping and localization algorithms at Unity Drive Innovation.