Vision-Language-Action (VLA) models have shown remarkable promise in generalized robotic
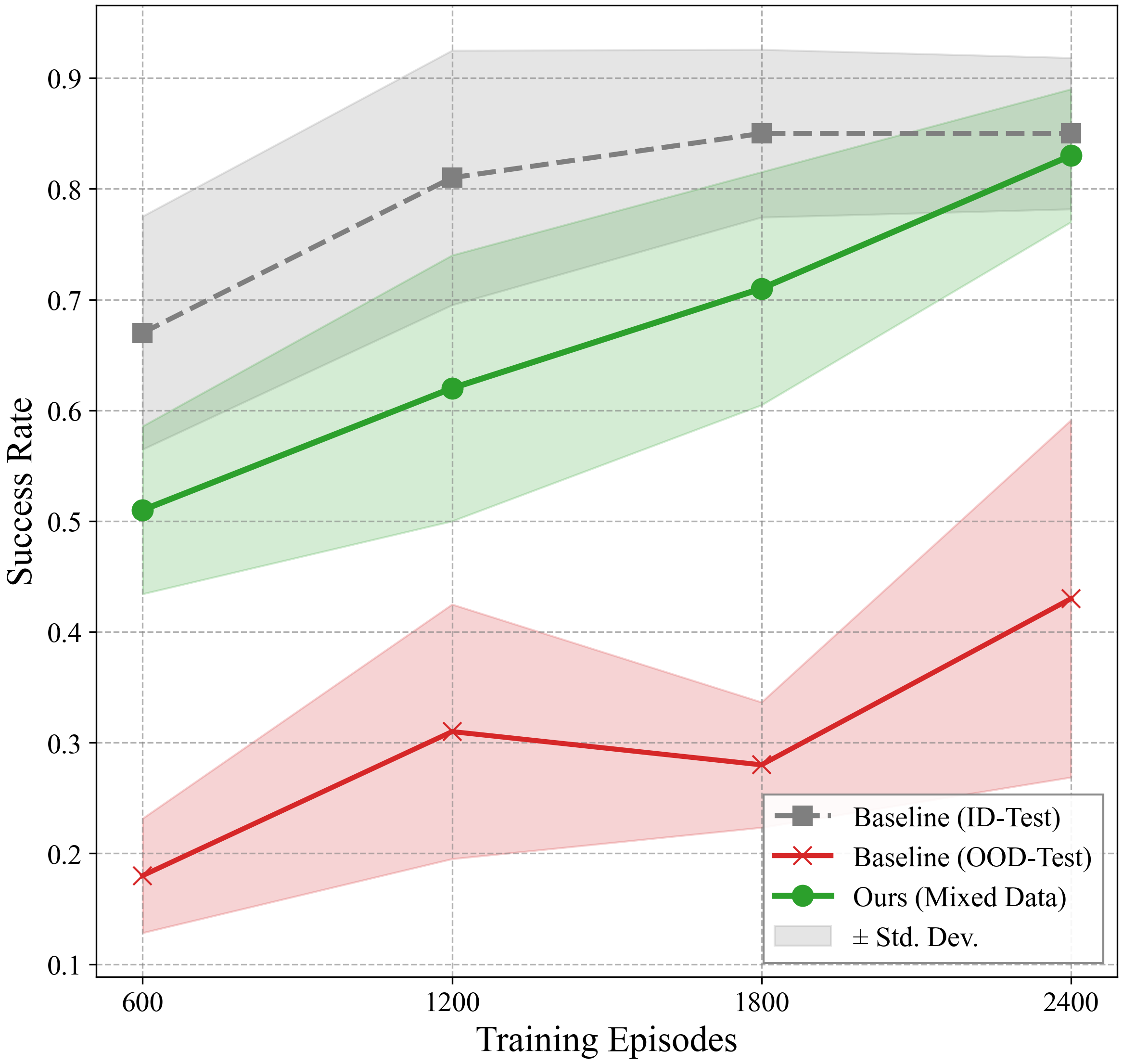
manipulation. However, their spatial generalization remains fragile — a
slight perturbation in camera pose or object configuration often leads to catastrophic
failure. We argue that simply increasing the number of viewpoints is insufficient.
Models fall into the trap of Shortcut Learning, exploiting spurious
camera–robot–object regularities rather than learning true spatial
relationships.
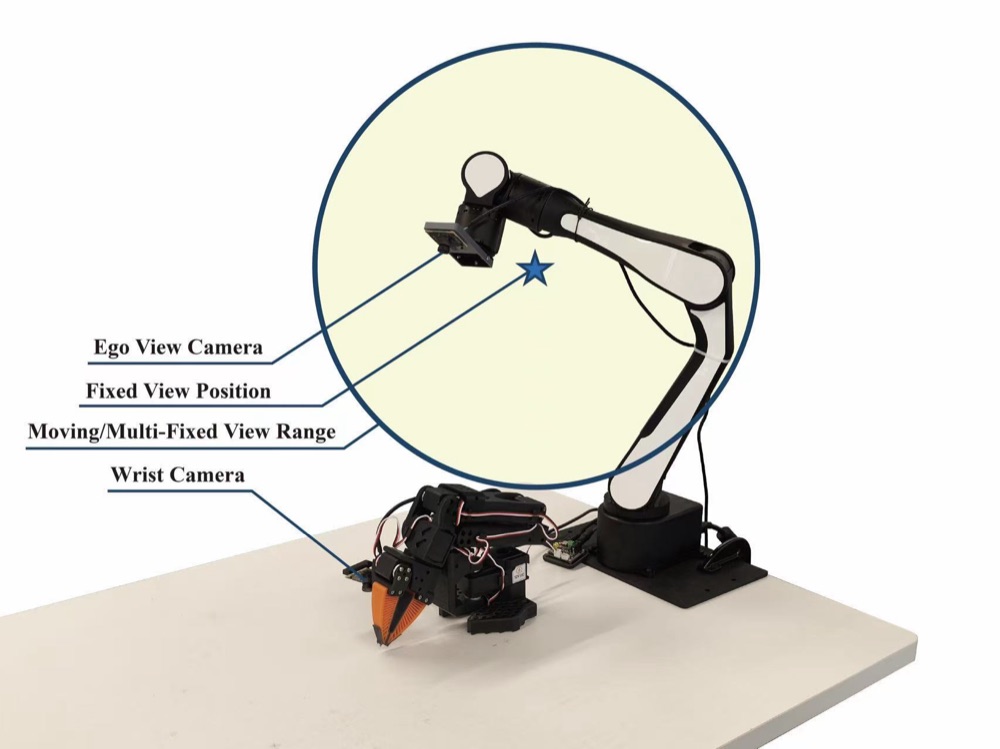
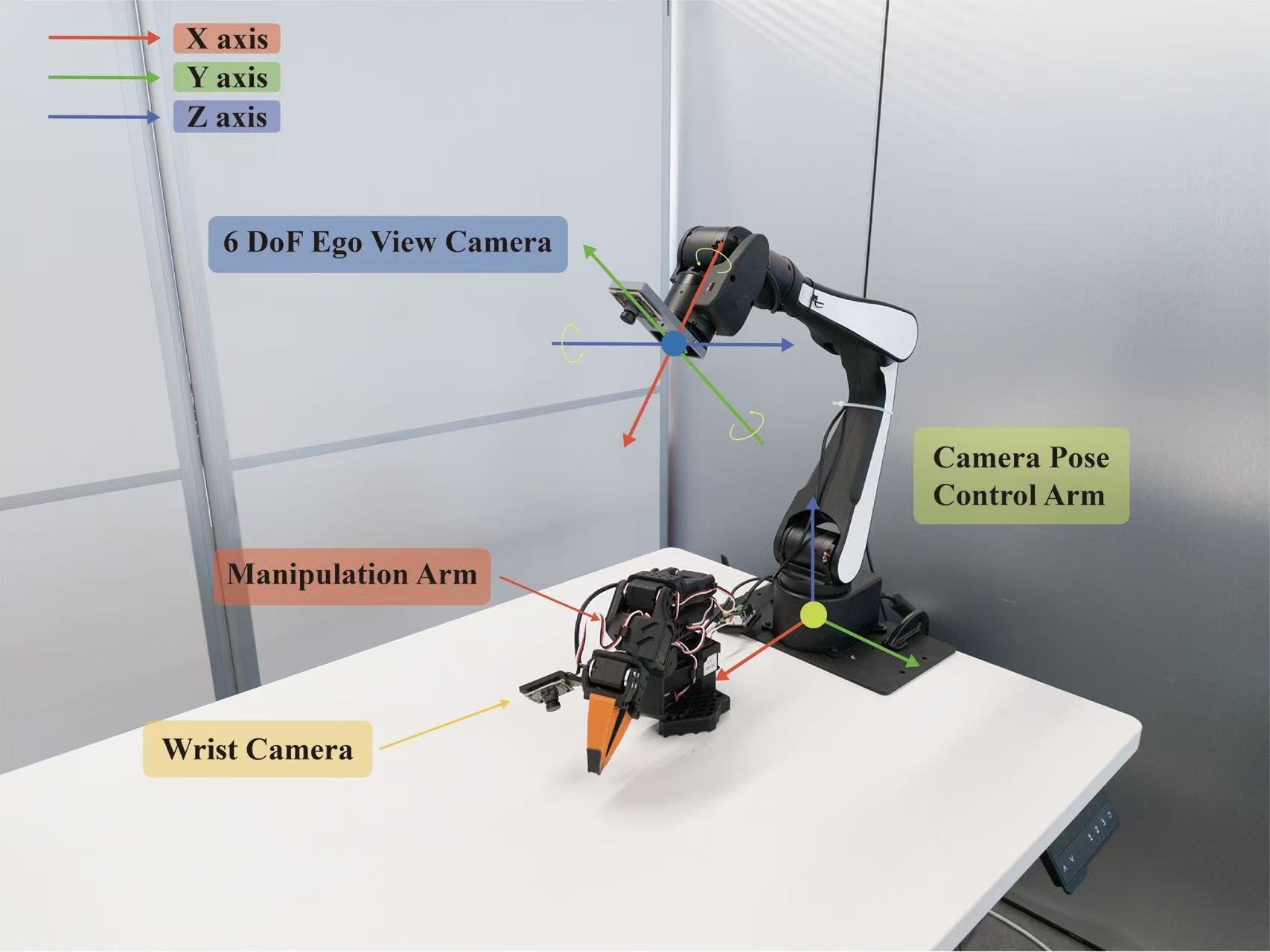
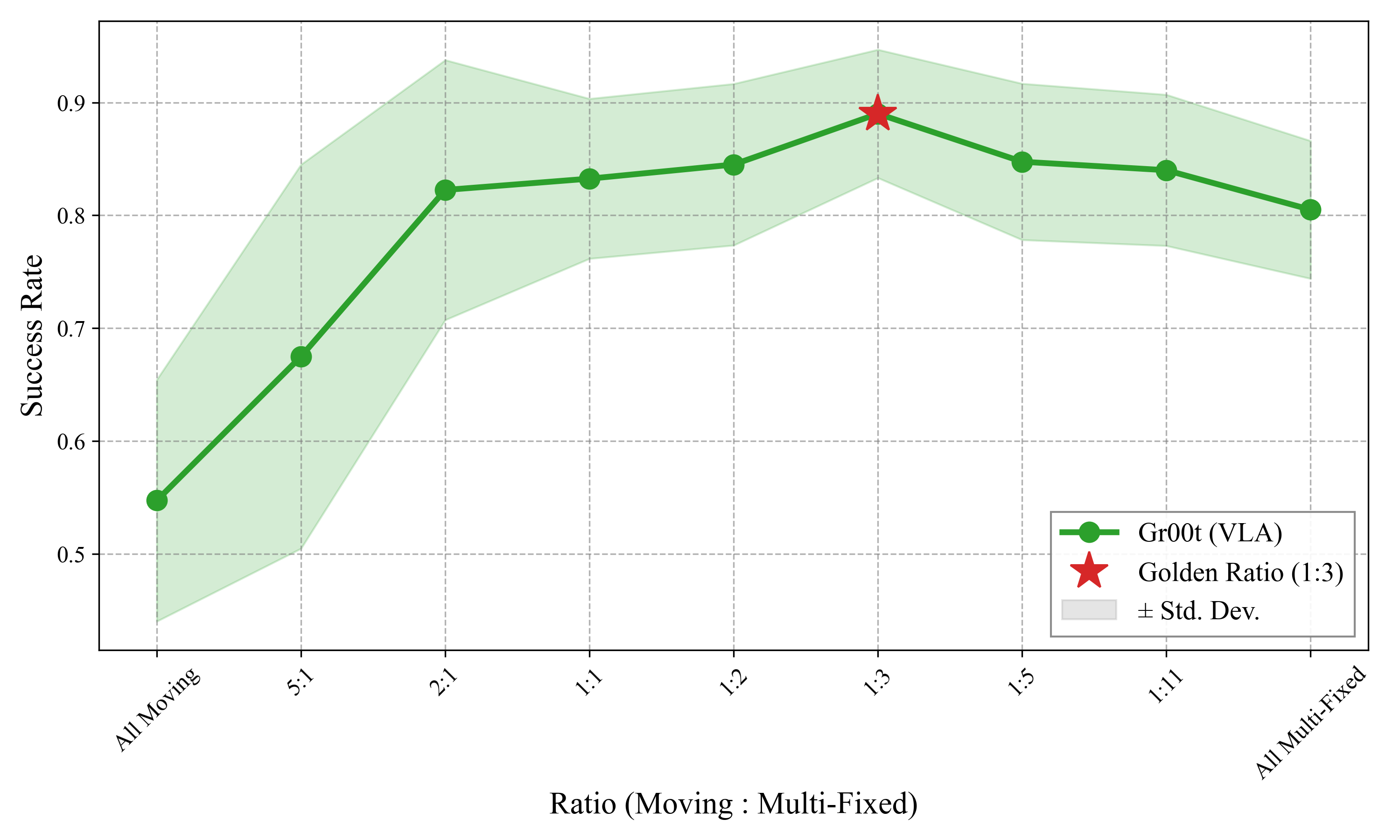
We propose a data-centric solution. Using a dual-arm setup — one arm manipulates,
the other carries a mobile environmental camera — we systematically evaluate three
data distribution patterns: Fixed, Multi-Fixed, and Moving Views.
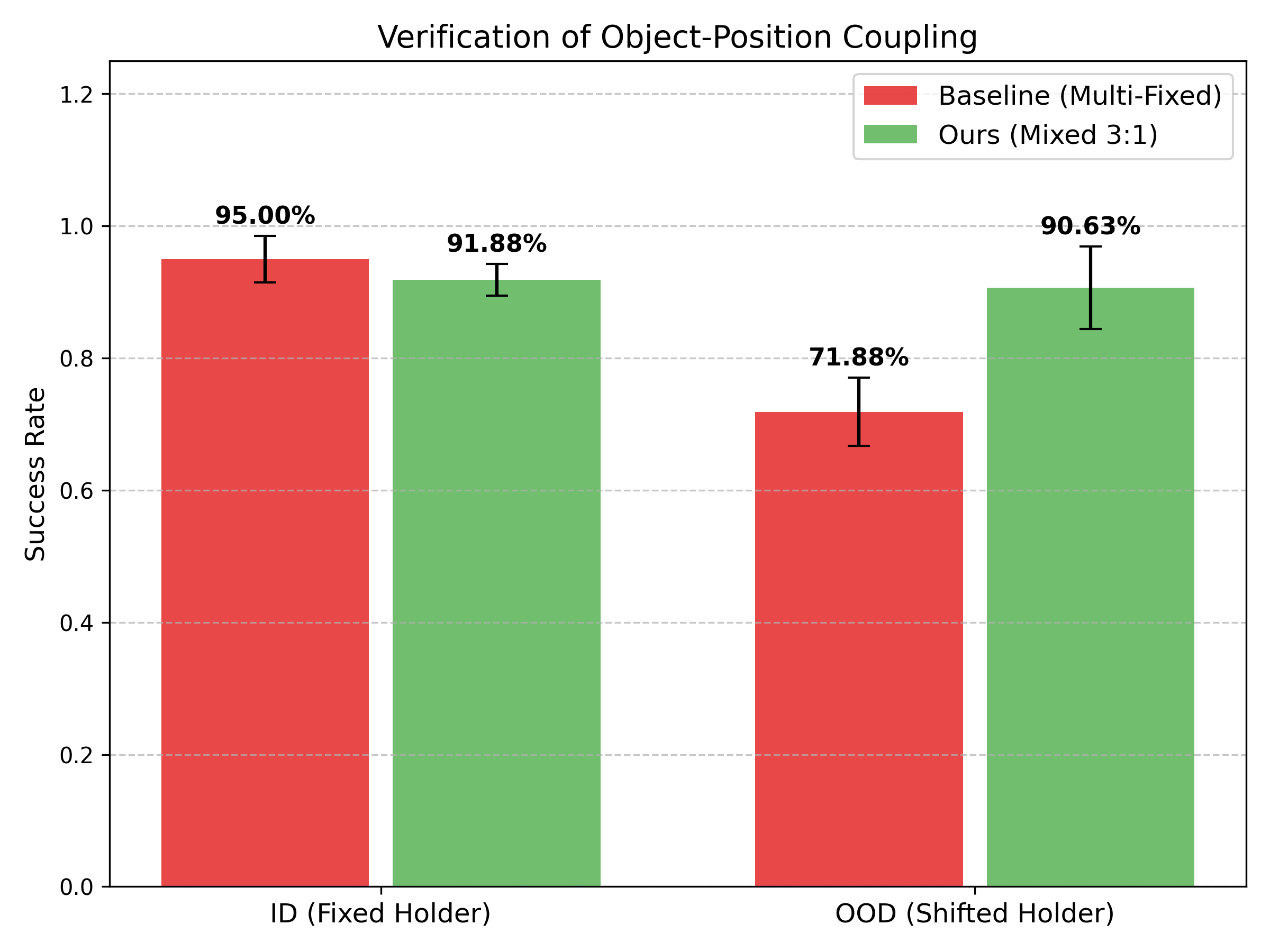
A hybrid strategy that mixes continuous camera motion with diverse static viewpoints
substantially reduces spurious correlations while maintaining training stability.
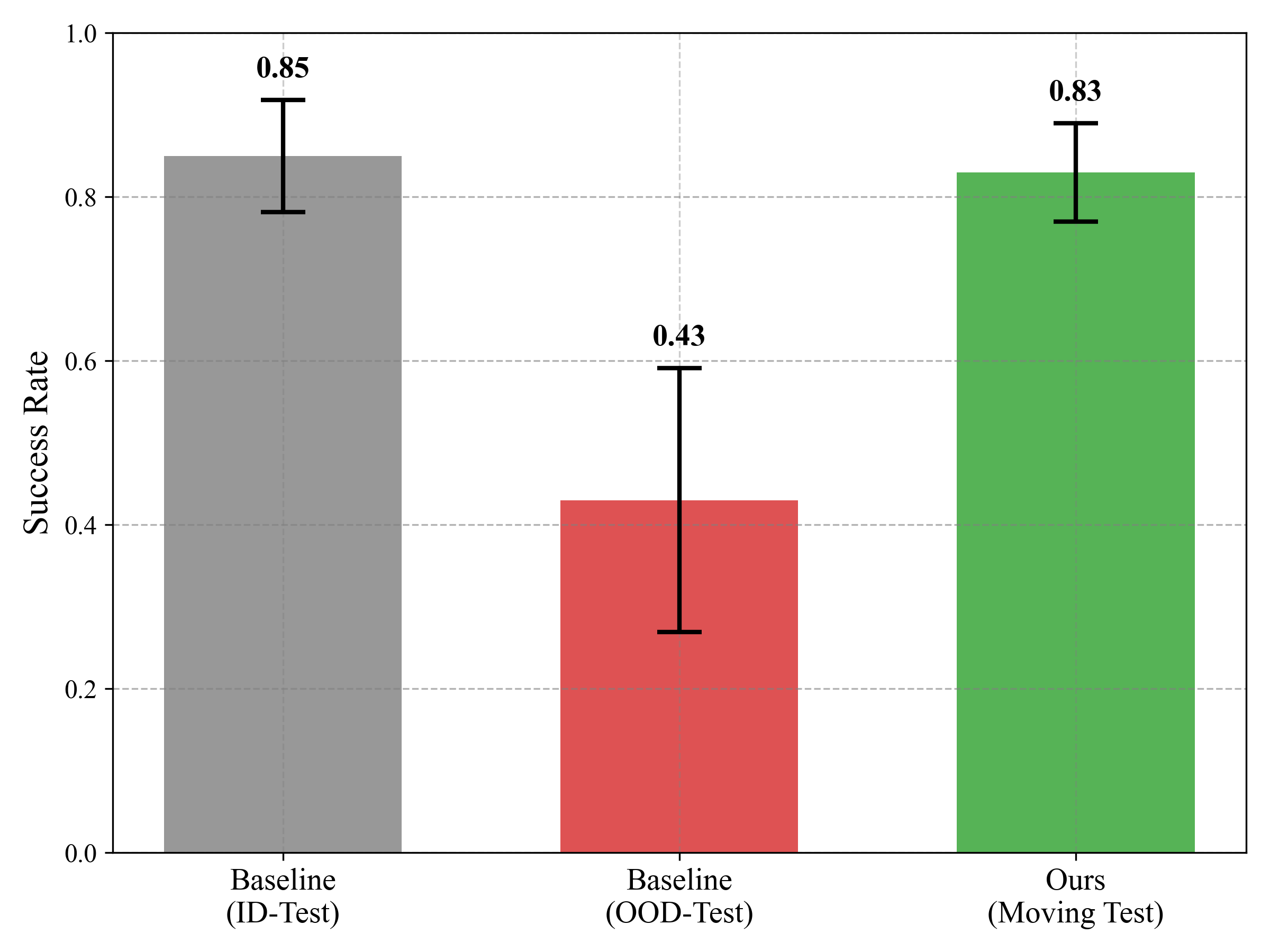
Our experiments show the strategy enables VLAs to generalize to unseen camera poses and
object configurations where adding more static viewpoints alone fails. Crucially,
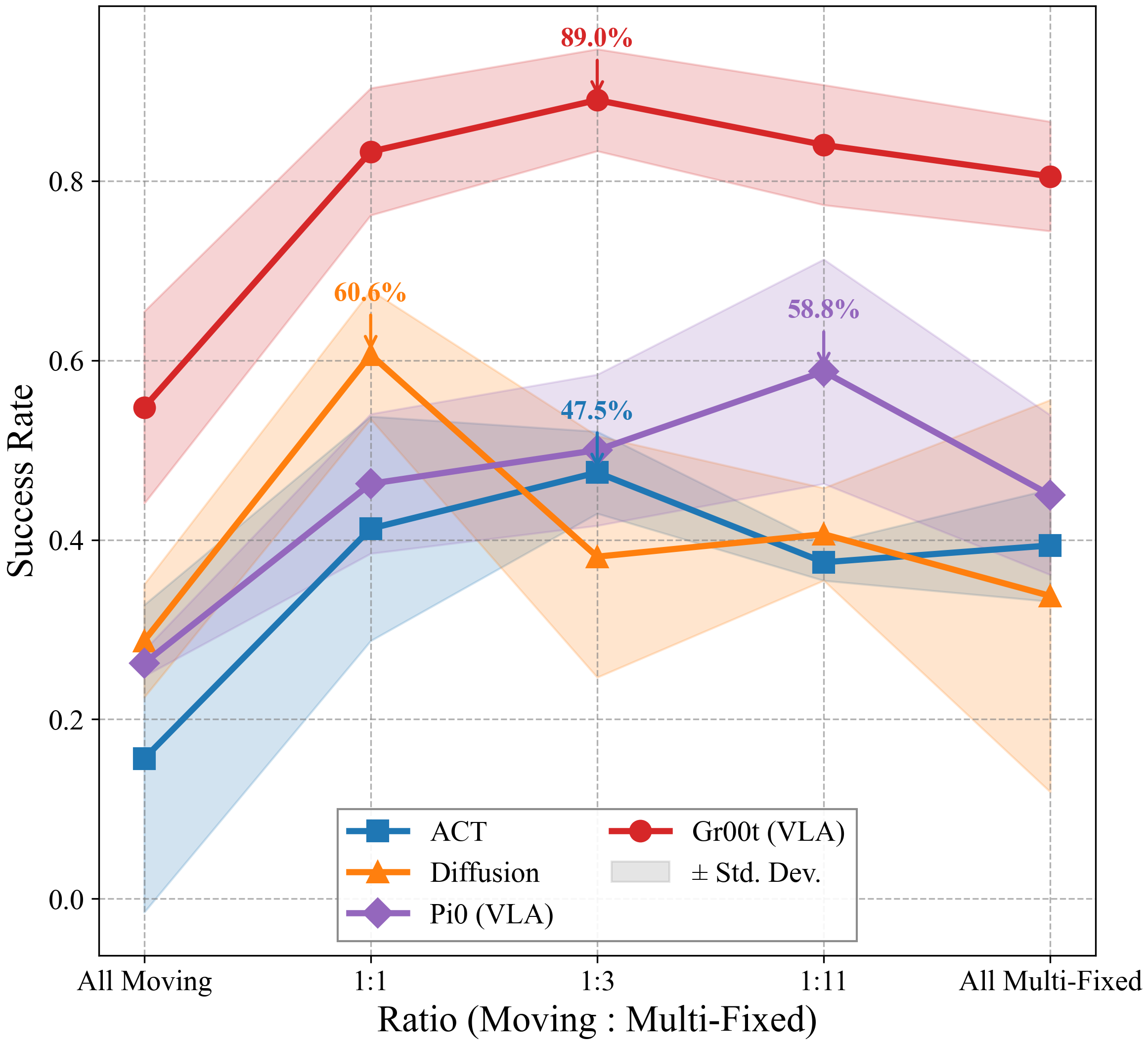
susceptibility to shortcut learning is a universal property across architectures:
ACT, Diffusion Policy, and VLA models including Pi0 and Gr00t all benefit
significantly from the mixed data strategy.