Hello, I'm Yilong Zhu
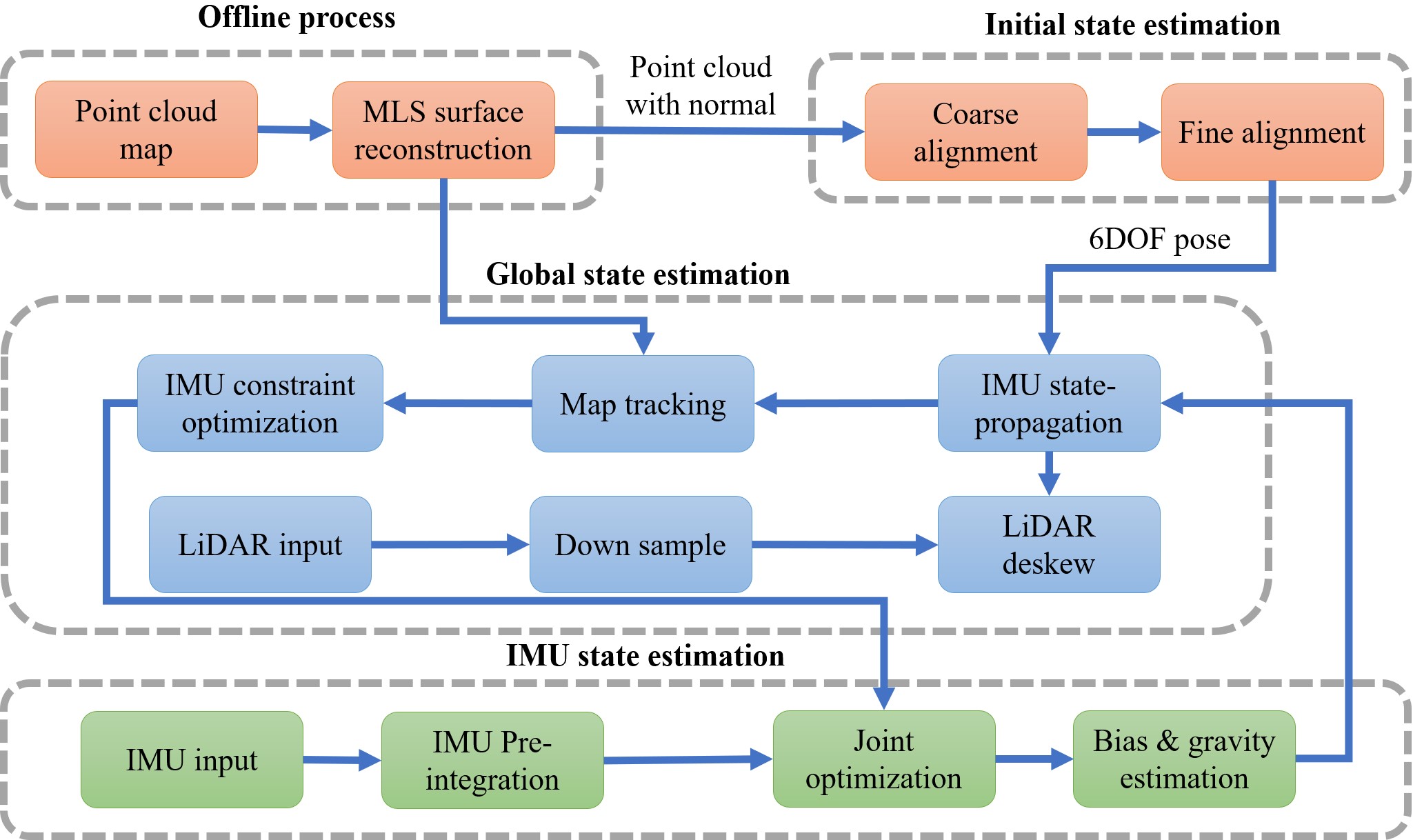
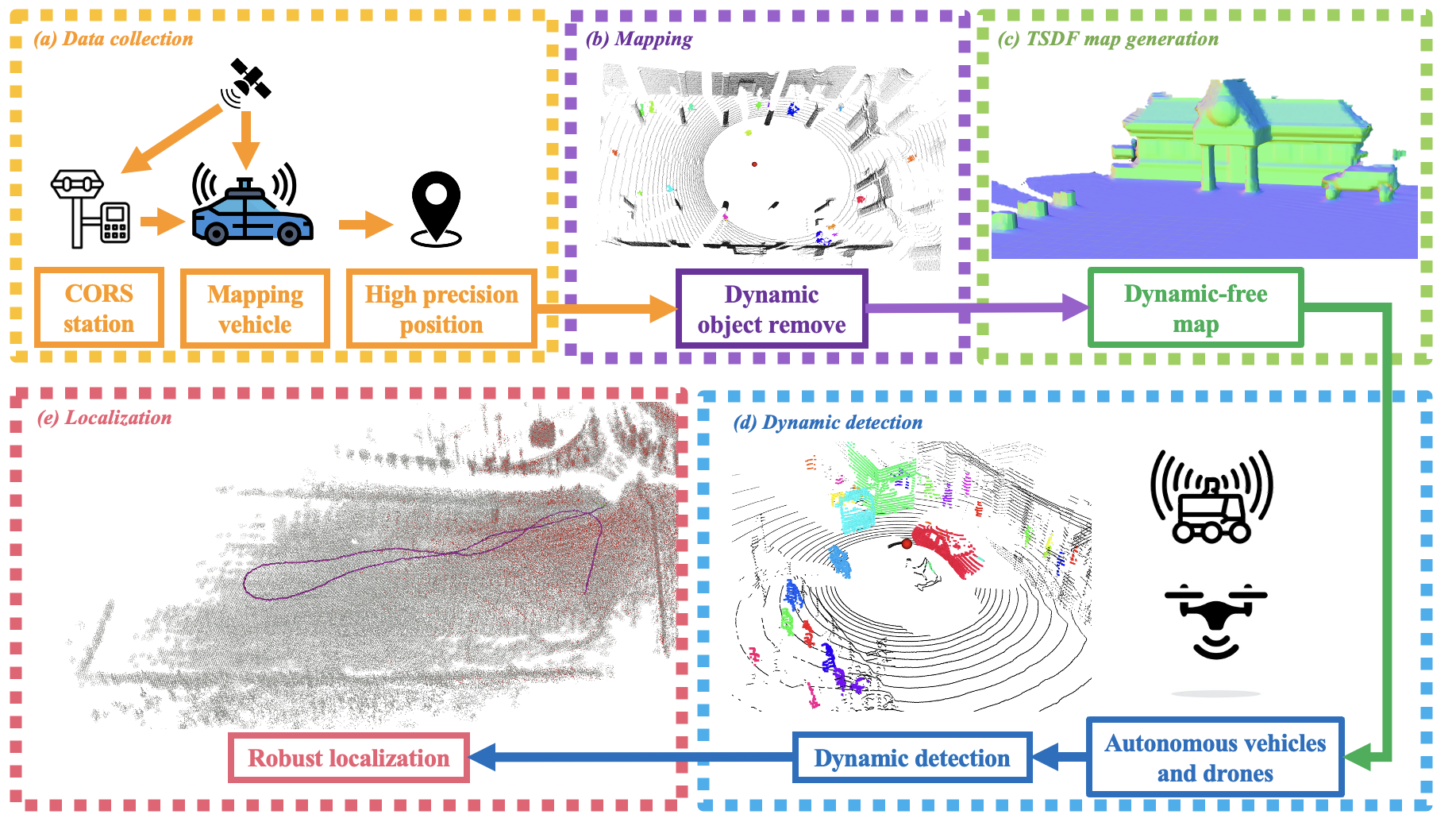
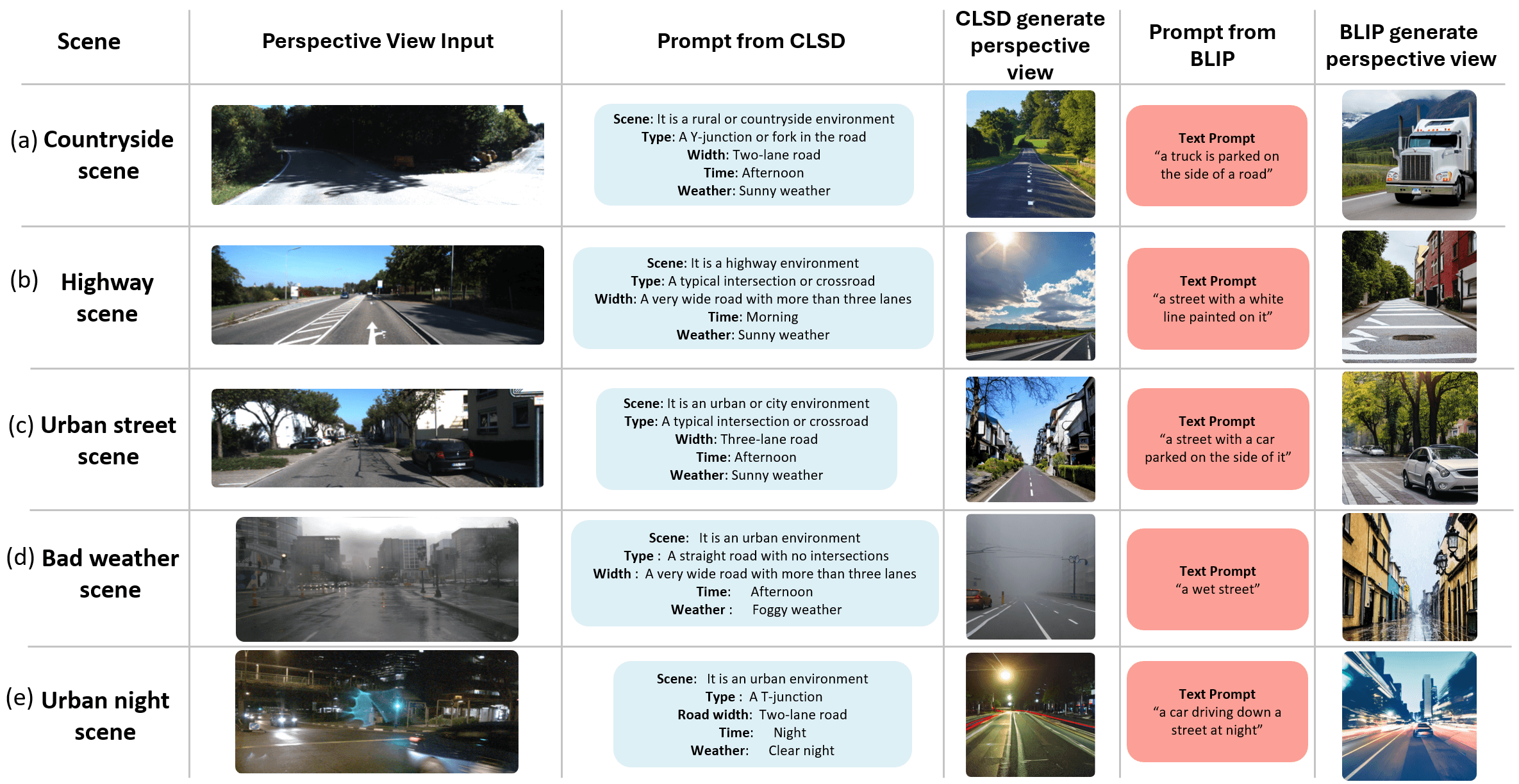
I am a Ph.D. candidate in the Aerial Robotics Group at the Hong Kong University of Science and Technology (HKUST), under the supervision of Prof. Shaojie Shen. My research centers on navigation systems for autonomous platforms, with emphasis on robust localization, mapping, and cross-view perception.
Currently, I am a VLA Research Intern at China Merchants Lion Rock AI Lab, working on Vision-Language-Action models for robotic systems.
Prior to pursuing my Ph.D., I served as Algorithm Leader in the Mapping and Localization Group at Unity Drive Innovation, where I led the development of multi-sensor localization systems integrating LiDAR, UWB, and inertial measurements.
My work has been published in premier robotics journals including T-RO and IJRR. I hold multiple patents in localization technologies and serve as a reviewer for ICRA, IROS, and T-RO.